分布式文件系統
發布時間:
2022-03-30 13:38:38
Google公司的三駕馬車GFS�����、Bigtable和MapReduce經常被大家看作是云計算的經典之作����,Amazon公司的Dynamo和開源項目Hadoop也是云計算世界里的明星產品��,實際上從技術角度來看它們都屬于分布式系統的范疇��。
分布式文件系統是如何發展起來的呢?
從20世紀70年代誕生至今�,大致上可以將分布式文件系統的發展歷程劃分為四個階段�����。1990年之前的分布式文件系統主要以提供標準接口的遠程文件訪問為目的����,比較關注系統性能和可靠性�����。這一階段的典型代表包括Sun公司研制的NFS(NetworkFile System)和美國卡內基梅隆大學開發的AFS(Andrew File System)���。
1990年到1995年期間���,互聯網逐步得到推廣應用����,網絡中傳輸實時多媒體數據的需求和應用也逐漸流行�,這一階段出現了不少為了實現上述需求而開發設計的分布式文件系統�,例如加利福尼亞大學研制的xFS(x File System)和IBM公司針對AIX操作系統開發的TigerShark�����。
1995年到2000年期間��,網絡技術和存儲技術持續發展����,NAS和SAN等新的存儲技術開始得到大量應用��,與之相應的分布式文件系統也應運而生�����,例如美國明尼蘇達大學研制的GFS(Global File System)和IBM公司在TigerSpark基礎上開發的GPFS(General Parallel File System)�����。
進入21世紀以來����,隨著網格計算和云計算技術的發展���,以Google公司為代表的軟件公司和研究機構針對Web應用的特色��,陸續推出了新型的分布式文件系統����。這其中最為著名的當屬Google公司的GFS(Google File System)和Hadoop開源項目的HDFS(Hadoop Distributed File System)�。
注意上面提到了兩個GFS���,一個是明尼蘇達大學研制的Global File System����,另一個是Google公司開發的Google File System��,后續我們提到的GFS都是特指后者�����,不再專門說明�����。
看起來����,好像進入21世紀之后的分布式文件系統才與云計算產生了交集�,是這樣嗎?
應該說�,GFS和HDFS都是在云計算時代應運而生的產物��,它們與傳統的分布式文件系統有很大的不同�,更能夠滿足云計算的需求�����。
但是��,GFS的新穎之處并不在于它采用了多么令人驚訝的新技術�����,而在于它采用廉價的商用計算機集群構建分布式文件系統�,在降低成本的同時經受了實際應用的考驗�。
與傳統的分布式文件系統相比�,GFS有哪些新的設計需求呢?
在性能�����、伸縮性�����、可靠性等方面��,GFS的設計目標與傳統的分布式文件系統沒有什么區別;但是考慮Google各種應用的實際情況后�����,GFS在許多方面的設計目標又具有鮮明的特色�����。這主要體現在下述方面�����。
(1)Google的數據中心均采用廉價的計算機和IDE硬盤構建�,因此硬件故障是一種常見的狀況��,在軟件設計上必須提高容錯能力�。
(2)系統需要處理數以百萬計的文件�,大多數是100MB或更大���,其中出現GB級別的文件也不奇怪�����,必須在設計時充分考慮這些因素���。
(3)系統主要考慮支持兩種讀操作:大規模數據流讀和小規模隨機讀���。前者通常連續讀取1MB或更多數據��,后者通常讀取幾kB數據�����。
(4)系統中存在兩種寫操作:大規模順序寫和小規模隨機寫�����。前者通常連續寫入1MB或更多數據����,需要在設計時考慮性能優化���。
(5)經常會出現多個應用程序同時向同一個文件進行追加寫操作���,必須保證這些并發操作的正確性����。
(6)希望系統在針對大數據量操作時獲得高性能���,不關注單個讀寫操作所花費的時間�。
GFS為應用程序提供了哪些訪問接口?
GFS提供了一個類似傳統文件系統的接口����,按照層次型的目錄樹來管理文件�,并提供傳統的Create����、Delete����、Open�、Close�、Read和Write操作����。除此之外����,GFS還專門提供了Snapshot和Record Append兩種操作�。其中Snapshot以最小的開銷創建一個目錄或文件的副本�����,Record Append則用來保證多個應用程序同時對文件進行追加寫操作時的正確性�����。
GFS采用了怎樣的系統架構?
如圖1所示�����,一個GFS的集群包括一個主服務器(master)和多個塊服務器(chunk server)����,能夠同時為多個客戶端應用程序(Application)提供文件服務�����。每個服務器或應用程序都是運行在Linux服務器中的一個進程���,只要性能允許����,可以將服務器進程和應用進程運行在同一個物理服務器上���。
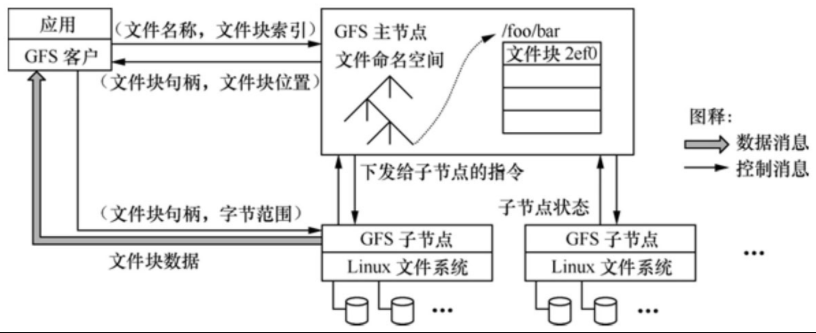
圖1 GFS的系統架構
GFS中文件劃分為固定大小的塊���,每個塊在創建時由主服務器分配一個64位的句柄�。塊服務器將塊以Linux文件的形式保存在本地硬盤上����,并通過句柄實現對其指定的字節范圍進行讀寫的操作�����。缺省情況下��,GFS對每個塊在三個不同的塊服務器上保持三個備份����,用戶也可定制備份策略���。
主服務器負責維護所有文件系統的元數據���,包括命名空間��、存取控制信息�����、文件和塊的映射關系以及塊的物理位置等�。主服務器還負責管理文件系統���,包括塊的租用�、垃圾塊的回收以及塊在不同塊服務器之間的遷移�。此外�����,主服務器還周期性地與每個塊服務器通過心跳消息交互�,以監視運行狀態或下達命令���。應用程序采用GFS提供的API函數接口通過與主服務器和塊服務器的交互來實現對應用數據的讀寫���,應用與主服務器之間的交互僅限于元數據����,所有的數據操作都是直接與塊服務器交互的�。
GFS中應用和塊服務器都沒有針對數據采用緩存機制��。絕大多數應用的流數據都是大型文件�,因此在客戶端無法采用數據緩存機制;而塊服務器在Linux文件中已經采用了緩存機制���,因此也不需要重復實現塊的緩存了��。當然��,客戶端針對元數據還是采取了緩存機制����。
塊的大小是如何設計的?
這是一個關鍵設計參數��,GFS選擇了64MB��,該方案優點如下�。
(1)降低了客戶與主服務器之間的交互���。對于在同一塊之內讀寫操作需要的塊服務器信息���,客戶只需要向主服務器請求一次就可以了��,因此降低了客戶與主服務器之間的交互�。由于GFS的應用大多是面向大文件的����,因此這個優點體現得很明顯�����。
(2)降低了集群中的網絡負荷��。由于客戶的讀寫操作大多被限制在同一塊服務器之內���,客戶就不需要建立與多個塊服務器的TCP連接�,因此降低了網絡負荷��。
(3)減少了主服務器中元數據的存儲容量����。該方案的缺點如下:如果多個客戶同時訪問一個僅有幾個塊組成的小文件的話�,存儲該小文件的塊服務器就會成為性能瓶頸��。由于Google公司實際應用中絕大多數操作都是對大數據文件的讀取����,因此并沒有出現這樣的情況�。
GFS的讀操作是如何實現的?
讀操作的步驟如下��。
(1)客戶根據指定位置和塊大小計算得到文件中的塊索引;
(2)客戶將文件名和塊索引發給主服務器查詢對應的塊服務器及句柄;
(3)客戶將這些信息緩存在本地;
(4)客戶向最近的塊服務器發送讀請求�,包括塊句柄及讀取范圍;
(5)塊服務器返回客戶要求讀取的塊內容�����。GFS的寫操作又是如何實現的?
如圖2所示�,寫操作包括7個步驟:

圖2 GFS的寫操作
(1)客戶向主服務器查詢寫入塊對應的主副本及次副本所在的塊服務器����,主服務器通過租約從多個塊服務器中選擇主副本���。
(2)主服務器向客戶返回寫入塊的位置信息����。
(3)客戶將寫入數據推送到所有副本上��,每個塊服務器將這些數據保存在內部緩存中�����,直到數據被使用或過期���。
(4)客戶向主副本所在的塊服務器發送寫請求���。
(5)主副本將客戶的寫請求傳遞到所有的次副本�����。
(6)寫入完成后����,各次副本將完成情況反饋給主副本�。
(7)主副本將完成情況反饋給客戶�,如果出錯則重復(3)~(7)步驟�����。
HDFS的架構是怎樣的?
如圖3所示�,一個HDFS的集群包括一個名稱節點(NameNode)和多個數據節點(DataNode)�,能夠為多個客戶程序(Client)提供服務��。HDFS采用Java語言開發�����,因此任何支持Java的計算機都可以用來部署NameNode和DataNode�����。
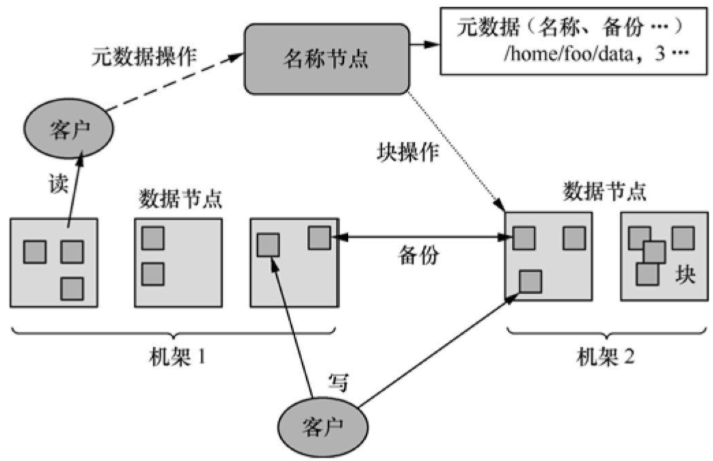
圖3 HDFS的架構
HDFS內部將文件劃分為若干個數據塊��,每個文件都存儲為一系列的數據塊�����,除最后一個外所有數據塊的大小是相同的���。缺省情況下�����,HDFS同時保存每個數據塊的三個副本���。
NameNode管理文件系統的命令空間�����,并維護文件到數據塊的映射關系��。DataNode負責處理客戶程序的文件讀寫請求���,并在NameNode統一調度下進行數據塊的創建�����、復制和刪除工作���。
大型的HDFS集群一般跨越多個機架�,不同機架之間通過交換機通信���。一般將數據塊的不同副本存放在不同的機架上�����,這樣可以有效防止整個機架失效時數據的丟失�����,還可以在執行讀操作時充分利用多機架的帶寬實現負載均衡�。
HDFS的讀操作是如何實現的?
如圖4所示�,客戶程序通過調用FileSystem對象的open()方法打開希望讀取的文件DistributedFileSystem實例�����,后者通過遠程進程調用訪問NameNode得到文件起始塊的位置�。DistributedFileSystem實例返回一個輸入流FSDataInputStream對象給客戶程序以讀取數據��,該輸入流對象專門封裝一個DFSInputStream對象管理NameNode和DataNode���。
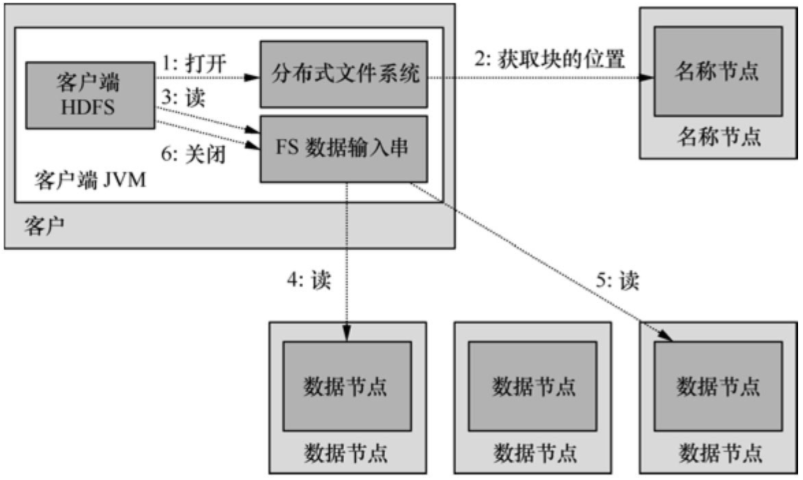
圖4 HDFS的讀操作
客戶程序對該輸入流對象調用read()方法�����,DFSInputStream對象即連接到距離最近的DataNode��,通過反復調用read()就可以將數據塊從DataNode傳輸到客戶程序�。到達塊的末端后���,DFSInputStream會關閉與該DataNode的連接�,轉而尋找下一個塊的最佳DataNode���。所有的數據塊都讀取完成后會調用FSDataInputStream對象的close()方法結束本次讀操作����。
HDFS的寫操作又是如何實現的?
如圖5所示��,客戶程序通過對DistributedFileSystem對象調用create()方法來創建文件��,該對象同時對NameNode創建一個遠程進程進程調用�����,在文件系統的命名空間中創建新文件�����。之后DistributedFileSystem向客戶程序返回一個FSDataOutputStream對象�,由此客戶端開始寫入數據���。同時還會封裝一個DFSOutputStream對象負責管理NameNode和DataNode���。
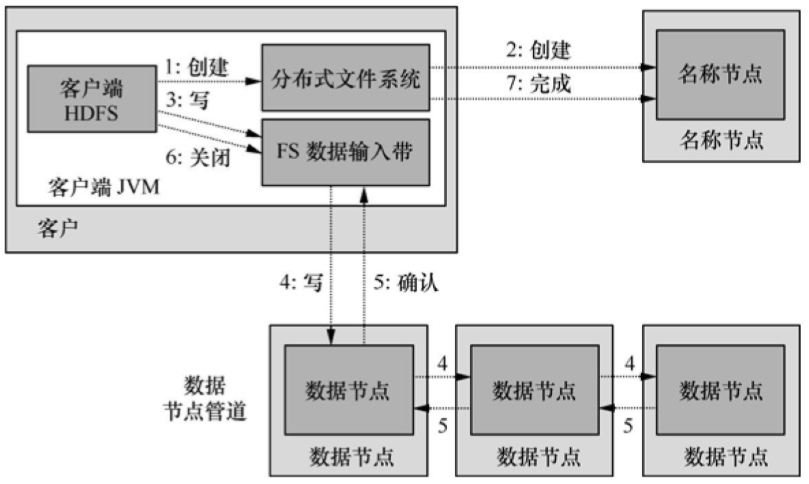
圖5 HDFS的寫操作
在數據寫入過程中��,DFSOutputStream將寫入數據劃分為多個數據包���,并采用數據隊列方式向多個DataNode寫入副本�,收到確認消息后繼續上述過程寫入其他數據塊���。所有數據塊寫入完成后會調用close()方法結束本次寫入操作����,并通知NameNode��。
看起來HDFS與GFS非常相似啊���,它們是什么關系呢?
Google在一份公開發布的論文中介紹了GFS的基本原理��,但是并沒有公開其源代碼���,Hadoop開源項目參考GFS公開的設計文檔設計實現了HDFS�,所以兩者看起來是非常相似的��。
一般認為HDFS是GFS的一個簡化版的實現�����,兩者有很多相似之處�����,例如都采用單主服務器和多數據服務器的架構��、都采用數據塊的方式來組織和管理文件���。但是兩者還是有不少差異的�����,例如HDFS不支持Record Append和Snapshot操作����。
上一篇:
HCIE-Routing & Switching切換HCIE-Datacom補充公告
下一篇:
什么是分布式系統


 18922156670
18922156670
























